












인텔의 제온 스케일러블 프로세서(Xeon Scalable Processor) 제품군은 기존에 지원 소켓 수와 기능을 기준으로 나뉘어 있던 제온 E5, E7 프로세서 제품군을 통합, 재구성해 새로운 브랜드로 선보인다. 제품군 내에서는 코어 수나 기술적 특징을 기반으로 플래티넘, 골드, 실버, 브론즈 등으로 나뉘어, 고객에 좀 더 ‘확장성’에 집중한 선택이 가능하도록 한 것이 특징이다. 그리고 이 중 최상위 모델인 ‘제온 플래티넘 8100 시리즈 프로세서’는 프로세서 당 최대 28코어와 함께, 8소켓 지원 구성을 갖췄다.
새로운 제온 스케일러블 프로세서는 ‘스카이레이크(Skylake)’ 아키텍처를 기반으로 해, 새로운 메시(Mesh) 아키텍처를 채택해 프로세서 내부의 자원들에 접근함에 있어 향상된 대역폭과 지연시간 감소를 제공한다. 또한 캐시 동작 방식과 구성이 변경되었으며 AVX512 명령어 셋 등이 추가되었으며, 하드웨어 가속 지원 기능들의 성능도 올라갔다. 이와 함께, 플랫폼 차원에서도 칩셋에 기본 네트워크 인터페이스 구성이 강화되고 QAT 가속기가 내장되었으며, NVMe에서의 RAID 구성 등도 지원된다.
 |
▲ 인텔은 AI를 위한 데이터센터 구축을 위해 필요한 대부분의 기술을 가지고 있다
최근 주목받고 있는 AI 관련 영역에서, 인텔은 폭넓은 영역의 ‘인텔 너바나(Intel Nervana)’ 포트폴리오를 갖추고 있다고 소개했다. 하드웨어 부분에서는 제온과 제온파이 프로세서, FPGA와 너바나의 가속기 등과 함께 메모리와 스토리지, 네트워킹 등의 인프라 전반을 모두 포함하며, 소프트웨어에서는 DAAL이나 MKL 등의 라이브러리와 플랫폼 등을 포함한다. 이 포트폴리오들은 현재 업계에서 널리 사용되는 다양한 프레임워크를 인텔 기반 시스템에서 최적의 효율로 구동할 수 있도록 해, 사용자 경험을 향상시키게 된다.
데이터센터에서 AI를 위한 인프라 구축에 있어, 학습과 추론 양 쪽에서 가장 범용적인 인프라 구성에는 제온 스케일러블 프로세서가 기반이 되며, 높은 수준의 병렬화된 워크로드 특성을 갖춘 딥러닝 트레이닝 부분을 위해서는 제온파이 프로세서가 준비되어 있다. 또한 지연 시간에 민감한 리얼타임 딥러닝 추론 등의 특별한 요구사항에는 인텔의 FPGA를 통한 가속 구성을 제시하고 있으며, 너바나의 기술을 기반으로 한 ‘Crest 제품군’도 딥러닝을 위한 솔루션으로 준비되고 있다.
인텔은 AI 관련 성능에서, 제온 플래티넘 8180 프로세서가 4년 전의 E5-2697 v2 대비 Caffe ResNet-50 추론 에서 18배의 성능을, Caffe AlexNet 트레이닝 성능에서는 최대 19배의 성능을 제공한다고 밝혔다. 또한 당장 이전 세대 대비의 성능 향상도 만만치 않은데, 제온 플래티넘 8180 프로세서는 E5-2699 v4와 비교할 때 Neon ResNet 18 추론 성능에서 2.4배, Neon ResNet 18 트레이닝에서는 2.2배의 성능 향상을 제공하고 있다고 덧붙였다.
 |
▲ 제온 스케일러블 프로세서는 AI를 위한 연산 역량에서 큰 개선을 이뤄냈다
 |
▲ 대역폭 측면에서도 높은 수준의 성능 향상을 확인할 수 있다
AI 워크로드 성능 향상의 주요 요인으로는 컴퓨트 역량과 연결 대역폭, 소프트웨어 최적화 정도가 꼽힌다. 그리고 컴퓨트 부분에서 제온 스케일러블 프로세서는 더 높은 연산 성능과 향상된 병렬화 수준, 더 많은 코어 수 제공 등의 향상된 부분을 제공한다고 소개되었다. 1소켓 제온 플래티넘 8180 프로세서는 SGEMM FP32에서 최대 3570 GFLOPS, IGEMM Int8에서 5185 GOPS 성능을 제공하며, 최대 두 개의 FMA를 갖춘 AVX-512로 더 향상된 병렬화 환경을 제공하고, 이전 세대보다 늘어난 최대 28개 코어 구성을 제공하고 있다.
AI 관련 워크로드에 있어 가장 많은 사이클이 소비되는 부분으로는 ‘합성곱(Convolution)’이 꼽혔는데, 추론에 있어 60~85%의 사이클이 이 합성곱에 소비될 정도다. 이에 제온 스케일러블 프로세서는 이전 세대 대비 정수 행렬곱(Matrix Multiply) 성능을 크게 올렸으며, 제온 플래티넘 8180의 SGEMM FP32 성능은 E5-2699 v4 대비 2.3배, IGEMM INT8 성능은 MKL 2018 적용시 3.4배까지 향상된다. 또한 AVX-512는 Caffe GoogleNet에서 37%, AlexNet에서는 65% 성능 향상을 제공하며, 전반적으로는 컴퓨트 영역 레이어에서 이전 세대 대비 최대 2.4배의 성능 향상을 제공한다고 소개했다.
AI 워크로드를 위한 ‘대역폭’ 측면에서, 제온 스케일러블 프로세서의 강점은 더 넓은 대역폭과 낮은 지연시간, 효율적인 대용량 캐시 제공 등이 꼽힌다. 제온 스케일러블 프로세서는 소켓당 6채널 DDR4 메모리 컨트롤러와 새로운 메시 아키텍처로 내부 대역폭을 확장했으며, 코어당 1MB의 MLC 캐시 또한 AI 워크로드에 유리한 측면을 제공한다고 덧붙였다. 그리고 이런 특징은 ReLU나 Pooling 레이어 등 대역폭 영역의 레이어에서 이전 세대 대비 최대 2.2배의 성능 향상을 제공한다고 소개했다.
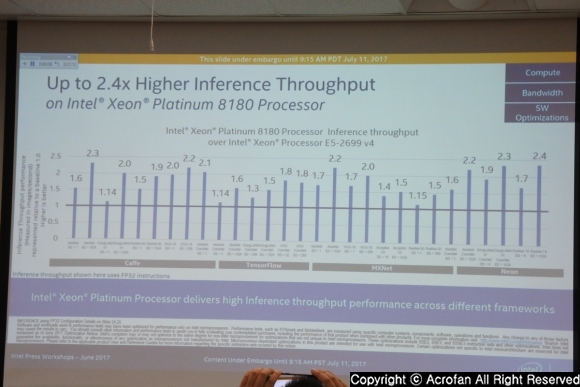 |
▲ 직전 세대와 비교해도, 새로운 프로세서는 추론에서 최대 2.4배의 성능 향상을 제공한다
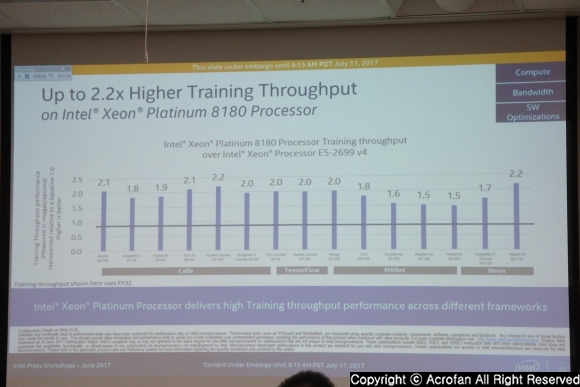 |
▲ 트레이닝 성능에서도, 이전 세대 대비 두 배 넘는 성능 향상을 선보였다
하드웨어의 발전과 함께 중요한 것이, 최신 하드웨어의 역량을 극대화할 수 있는 소프트웨어 최적화 부분이다. 인텔은 이 부분에서, 최신 하드웨어 아키텍처를 최대한 활용할 수 있는 소프트웨어 라이브러리와 분석 도구 등을 제공하고 있다고 소개했다. 그리고 4~5년 전의 성능과 비교했을 때, 최적화된 프레임워크와 라이브러리를 적용한 최신 제온 플래티넘 8180 프로세서는, 기본 소프트웨어 모델의 제온 E5-2699 v3 대비 추론 성능은 138배, 트레이닝은 113배 높은 성능을 보일 정도라고 강조했다.
컴퓨트와 대역폭 등 하드웨어 영역과 소프트웨어 개선이 결합되어, 제온 스케일러블 프로세서는 이전 세대 대비 추론에서는 최대 2.4배 높은 성능을 제공할 수 있는 것으로 소개되었다. 또한 트레이닝 처리량에서도 제온 플래티넘 8180은 E5-2699 v4 대비 주요 프레임워크에서 적게는 1.5배, 많게는 2.2배의 성능을 보였으며, 트레이닝 시간 또한 크게는 절반 정도로 줄여 높은 생산성을 기대할 수 있게 한다고 밝혔다.
Copyright ⓒ Acrofan All Right Reserved.


 마이크로소프트, 이그나이트 2023에서 AI 미래 여는 혁신 ..
마이크로소프트, 이그나이트 2023에서 AI 미래 여는 혁신 .. 네이버 두 번째 IDC '각 세종', "초대규모 AI , 클라우드 등..
네이버 두 번째 IDC '각 세종', "초대규모 AI , 클라우드 등..
 로터스의 하이퍼 SUV 엘레트라, 국내 판매 가..
로터스의 하이퍼 SUV 엘레트라, 국내 판매 가.. 머스탱 60주년 역사와 함께한 포드의 발자..
머스탱 60주년 역사와 함께한 포드의 발자..