












인텔은 클라우드 컴퓨팅 이후의 시대를 ‘AI 컴퓨팅’으로 규정하고, AI 컴퓨팅 전반에 대응해 하드웨어와 소프트웨어, 엣지부터 데이터센터까지 폭넓은 제품 포트폴리오를 통해 지속적인 ‘선순환 구조’를 만들어 간다는 전략을 표방하고 있다. 그리고 이번 행사에서 인텔은 이를 뒷받침하는 최신 하드웨어 제품들과 함께, 소프트웨어 측면에서도 생태계 전반에 걸친 인텔 아키텍처와의 최적화 등을 제공하고 있다고 소개했다.
이번 행사에서는 인텔의 글로벌 차원에서의 전략 뿐 아니라, 일본과 주위에서의 AI 기술 관련 협력 사례 등도 소개되었다. 먼저, PFN(Preferred Networks Inc.)과 인텔은 딥러닝을 위한 오픈소스 프레임워크 Chainer의 인텔 아키텍처 기반 최적화를 위해 협력하기로 했다고 발표했다. 또한 AI 활용의 확산을 위한 연구소와 협력사, 고객사 등의 초청 세션과, 인텔과 파트너사들이 AI 관련 솔루션과 기술을 선보이는 데모 쇼케이스 등이 함께 진행되었다.
 |
▲ 나이디 샤펠 인텔 데이터센터 사업부 AI 제품 부문 시니어 디렉터
인텔의 데이터센터 사업부 AI 제품 부문 시니어 디렉터인 나이디 샤펠(Nidhi Chappell)은 이 자리에서 AI의 각 부분에 대응하는 인텔의 하드웨어 제품군에 대해 소개했다. 인텔은 AI를 메인프레임, 표준 기반 서버와 클라우드 컴퓨팅에 이은 새로운 흐름으로 보고 있으며, 데이터센터에서 AI 컴퓨트 사이클은 2020년까지 12배 성장이 기대되는 등 빠른 성장이 기대되고, 이런 추세의 가속화에 기여하고자 한다고 강조했다.
AI 관련으로 최근 주목받고 있는 부분으로는 ‘머신 러닝’ 이 꼽히지만, 이는 AI의 한 부분일 뿐이다. 인텔은 AI의 구성을 ‘머신 러닝(Machine Learning)’과 ‘추리 시스템(Reasoning systems)’으로 나누고, 이들을 구현하는 방법론 측면에서 머신 러닝에는 ‘딥 러닝(Deep Learning)’, ‘전통적인 머신 러닝’을, 추리 시스템에는 ‘메모리’ 기반과 ‘로직’ 기반으로 소개했다. 한편 인텔은 현재 이런 폭넓은 영역의 AI 관련 워크로드의 95% 이상이, 인텔 아키텍처 위에서 수행되고 있다고 덧붙였다.
그리고 인텔은 AI 관련 모든 영역에서 적합한 성격의 솔루션을 제공하고 있다는 점을 소개했다. 가장 기본적이고 보편적인 구성이라면 제온 프로세서 기반의 시스템이 있고, 가속화된 딥러닝을 위해서는 제온 파이를 제시하고 있다. 또한 제온과 FPGA 가속의 조합은 매우 낮은 지연 시간의 추론(Inference)을 가능하게 하며, 높은 신경망 네트워크 성능이 요구되는 경우에는 제온 기반의 시스템에 너바나의 기술을 기반으로 한 가속기 ‘레이크 크레스트(Lake Crest)’를 제안한다.
 |
▲ 너바나의 가속기가 제온에 통합된 제품이 등장할 예정이다
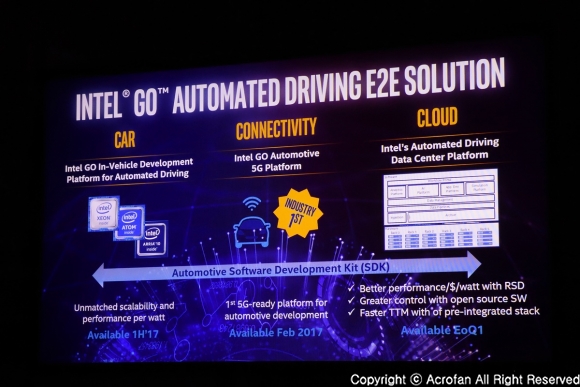 |
▲ 인텔의 GO E2E 솔루션은 자율주행차를 위한 모든 영역을 묶는 플랫폼을 제공한다
인텔은 현재 최신 제온 E5 프로세서 제품군이 3년 전과 비교할 때, 아파치 스파크(Apache Spark)의 수행 성능에 있어, 하드웨어 성능 향상과 소프트웨어 최적화에 힘입어 18배 향상되었다고 소개했다. 그리고 곧 등장을 앞둔 ‘스카이레이크’ 기반 제온은 AVX512 적용 등을 통한 성능 향상이 예고되고 있으며, 제온과 알테라의 ARRIA 10 FPGA를 하나의 패키징으로 구성한 제품도 준비되어, 높은 대역폭과 낮은 지연, 높은 에너지 효율을 제공할 것이라고 덧붙였다.
현 세대의 제온 파이는 ‘부팅 가능한’ 가속기로 HPC와 머신러닝, 딥러닝에 최적화된 성능을 제공한다. 최대 400GB의 직접 접근 가능한 메모리 구성이 가능하고, 32노드 확장에서 31배의 성능 향상이 가능한 고효율의 선형적 확장성도 제공한다. 이에 최신 제온 파이는 2016년 11월 기준 TOP500 리스트에서 향상된 성능의 80%를 담당했다고 덧붙였다. 그리고 올해 선보일 차세대 제온파이 ‘Knights Mill’은 현 세대보다 4배 향상된 딥러닝 성능을 제공할 것이라고 밝혔다.
딥러닝을 위한 인텔 너바나 플랫폼은 기존 너바나 기술 기반의 가속기 ‘Lake Crest’에 이어, 제온 프로세서와 가속기가 통합 구성되는 ‘Knights Crest’가 예고되어 있다. 그리고 인텔은 2020년까지 하드웨어 향상과 소프트웨어, 알고리즘 개선 등을 통해 현재보다 머신러닝에서의 트레이닝 성능을 100배 높이겠다는 목표를 제시한 바 있기도 하다. 한편 인텔은 ‘인텔 너바나 AI 위원회 (Intel Nervana AI board)’를 통해, AI가 올바른 방향으로 발전해 나갈 수 있도록 제안하고자 하고 있다고 덧붙였다.
이와 함께 최근 주목받고 있는 ‘자율주행차’ 관련에서도, 인텔은 차량 쪽의 ‘로컬 인텔리전스’와 클라우드 기반의 ‘글로벌 인텔리전스’, 연결에 이르기까지의 전반에 걸친 솔루션을 가지고 있고, 이를 하나의 플랫폼으로 연결하는 ‘Go’ 자율주행 E2E 솔루션을 소개했다. 또한 AI는 헬스케어 영역에서도 큰 변화를 만들어내고 있는데, 신약 개발, 난치병의 진단과 예방 등에서 몇 가지 사례가 이미 나타나고 있다고 소개되었다.
 |
▲ 아미르 코스롭샤히 인텔 AI 프로덕트 그룹 CTO
인텔의 AI 프로덕트 그룹 CTO인 아미르 코스롭샤히(Amir Khosrowshahi) 부사장은 이 자리에서 인텔의 AI 소프트웨어 부분에 대해 소개했다. 그는 ‘클라우드’ 이후의 시대를 ‘AI 시대’로 소개하며, AI는 이미 컨슈머, 헬스케어, 금융, 리테일, 정부, 에너지, 교통과 산업 등에서 다양한 형태로 비즈니스 변화를 만들고 있다고 밝혔다. 대표적인 사례로는, 헬스케어의 신약 개발이나 연구 등이, 금융은 부정행위 탐지 등이, 제조업은 자동화와 예측 관리가, 교통에는 자율주행차 등이 꼽힌다.
‘딥러닝’은 크게 ‘트레이닝’과 ‘추론’으로 구분된다. 그리고 이 중 데이터센터에서 긴 시간 동안 이루어지는 ‘트레이닝’은 방대한 데이터를 가지고, 적합한 신경망 모델을 기반으로 한 훈련을 통해 추론에 활용할 판단 기준을 세우게 된다. 그리고 이렇게 훈련된 모델은 추론에서 활용되어, 들어온 정보를 분석, 결과를 도출하게 된다. 이 때, ‘트레이닝’은 모델을 만들고 훈련하는 ‘데이터 사이언티스트’의 영역이며, ‘추론’은 이를 기반으로 애플리케이션을 구현하는 ‘개발자’의 영역이라고도 소개했다.
인텔은 AI 솔루션의 포트폴리오에 있어, 하드웨어에서부터 시작해 각종 솔루션들에 이르기까지 모든 영역에서 역량을 제공하고 있다고 소개했다. 여기에는 하드웨어를 최대한 활용할 수 있게 하는 MKL, MKL-DNN, 최적화된 파이썬 배포판 등의 퍼포먼스 라이브러리, 네온(Neon)이나 텐서플로우(TensorFlow), 카페(Caffe), 체이너(Chainer) 등의 프레임워크, 인텔 너바나 플랫폼에서의 도구와 SDK 들이 포함된다.
 |
▲ MKL-DNN이나 MLSL은 딥러닝 프레임워크의 성능 극대화를 위한 빌딩 블록을 제공한다
 |
▲ 툴과 프레임워크 포트폴리오에서는 인텔 뿐 아니라 다양한 오픈소스 프레임워크에 대한 지원도 포함되어 있다
딥러닝에 있어 딥러닝 프레임워크는 컴퓨트 빌딩블록의 알고리즘에 따라 하드웨어를 활용하게 되며, 이 때 빌딩 블록을 하드웨어에 최적화된 방식으로 구현할 수 있으면 하드웨어의 성능을 최대한 활용해, 효율을 높일 수 있다. 인텔은 이를 위해 연산 관련에는 인텔 아키텍처에 최적화된 MKL(Math Kernel Library)와 딥러닝을 위한 MKL-DNN(Deep Neural Networks), 커뮤니케이션 쪽으로는 MLSL(Machine Learning Scaling Library) 등을 제공하고 있다.
인텔은 인텔 아키텍처에서의 최적화된 AI 활용을 위해 다양한 툴과 프레임워크를 지원하고 있다. 이 중 MKL과 MKL-DNN은 연산과 딥러닝 등에서 아키텍처의 성능을 최대한 활용할 수 있게 하며, DAAL(Data Analytics Acceleration Library)는 알고리즘 레벨에서 객체지향 분산 환경에서의 데이터 분석 가속을 지원한다. 또한 인텔의 딥러닝 툴은 딥러닝 모델 디자인과 트레이닝, 배포의 가속화를 지원하며, 오픈소스 프레임워크의 최적화 지원 이외에도 인텔은 파이썬의 고유 배포판을 지원하고 있다고 덧붙였다.
생태계 기여 측면에서는 ‘인텔 너바나 AI 아카데미(Intel Nervana AI Academy)’를 통해 개발자 프로그램을 AI까지 확장했으며, AI에 최적화된 딥러닝 프레임워크, 교육 및 개발용 툴, 워크샵이나 웨비나 등 광범위한 교육 과정 및 리소스를 지원한다. 또한 고성능 딥러닝을 위한 인텔의 레퍼런스 프레임워크로는 ‘네온(NEON)’ 이 소개되었는데, 모든 하드웨어에 최적화된 딥러닝 프레임워크로, 커뮤니티를 통해 다양한 워크숍, 웨비나 등을 제공하고 있다고 밝혔다.
 |
▲ 도쿄공업대학 마쓰오카 사토시 교수
이어 도쿄공업대학(Tokyo Institute of Technology)의 마쓰오카 사토시(Satoshi Matsuoka) 교수가 일본의 AI를 위한 HPC 역량 강화 계획을 소개했다. 일본의 HPC로 잘 알려져 있는 것은 2010년 11월 발표된 츠바메(Tsubame) 시리즈가 있는데, 이 츠바메의 2.0은 인텔의 프로세서와 엔비디아의 GPU를 활용하여, 2013년의 츠바메 2.5에서는 5.7Pflops의 성능을 낸다고 소개했다. 또한 2011년 발표된 경(京, Kei) 슈퍼컴퓨터도 11.4Pflops 성능을 내지만, 츠바메 대비 유지비가 높은 특징이 있다고 덧붙였다.
2013년부터 계획된 JST-CREST의 ‘익스트림 빅데이터’ 프로젝트는 다양한 과학 관련 연산을 위한 슈퍼컴퓨터 기반의 클라우드를 구현하는 것을 목표로 제시하고 있다. 그리고 이 때 또 다른 고려점으로는 기존의 HPC 중심 프로세싱과, AI 관련의 빅데이터는 워크로드의 성격이 크게 다르다는 점이 꼽히는데, 이런 양쪽의 요구에 모두 효과적으로 대응할 수 있는 인프라를 갖추고자 하는 것도 중요한 부분으로 꼽혔다. 그리고 슈퍼컴퓨터의 구현과 효율에 있어서도, ‘경’은 네트워크 효율 향상 등으로 경쟁 시스템 대비 높은 효율을 구현한 바 있다고 덧붙였다.
AI와 빅데이터를 구현하기 위한 세 가지 축을 중심으로 볼 때 일본의 현재 상황은, 빅 데이터의 양이나 연구개발 역량, 소프트웨어 부분은 충분히 경쟁력이 있는 수준으로 평가받고 있지만, 이를 다루기 위한 ‘인프라’ 측면, 특히 대규모의 ‘클라우드’ 인프라 측면이 갖춰져 있지 않다고 지적했다. 그리고 일본의 해결책으로는, 당장 글로벌 사업자들의 대규모 클라우드를 그대로 따라가기보다는, 학계 등을 중심으로 HPC 기반의 인프라를 활용하고자 한다는 점이 제시되었다.
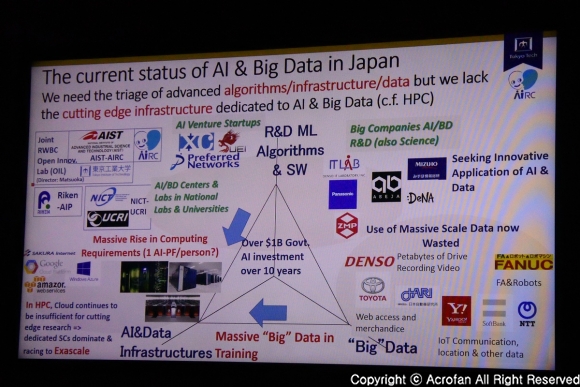 |
▲ 현재 일본의 AI 관련에서 부족한 ‘인프라’를 가장 빨리 채우는 방안으로 HPC가 꼽혔다
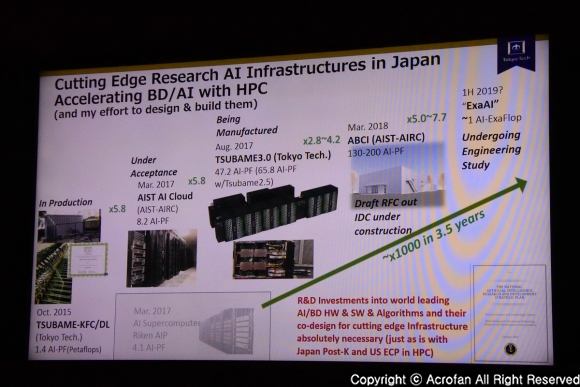 |
▲ AI를 위한 HPC 인프라 구축으로, 3.5년에 1000배 역량 강화의 계획을 제시했다
AIST AI Cloud(AAIC)의 ABCI 프로토타입은 엔비디아의 GPU와 인피니밴드 EDR 연결 구성으로 머신러닝과 딥러닝 등 다양한 AI 워크로드를 가속하도록 하는 구성을 갖추고 있는 것으로 알려졌다. 츠바메 또한 지속적으로 성능 향상과 함께, 운영에 요구되는 온도 조건을 완화시켜 운영 효율을 높이기도 했다. 이에 츠바메 3.0에서는 츠바메 2.5와 츠바메-KFC의 성과 등이 집약되어, 높은 성능과 최고 수준의 PUE 구현을 제시했다.
츠바메 3.0은 인텔 제온 프로세서와 엔비디아의 파스칼(Pascal) P100 GPU를 사용하는 SGI ICE XA 시스템을 기반으로, 인텔의 옴니패스 네트워크 연결과 DDN의 스토리지를 활용한다. 각 노드는 블레이드 형태로 구성되며, 데이터센터는 15개의 SGI ICE-XA 랙, 2개의 네트워크 랙, 3개의 DDN 스토리지 랙 등으로 구성되고, 컴퓨트 랙은 32도 정도의 온수를 사용한 수냉을 활용하고, PUE는 1.033에 이른다고 밝혔다. 한편 츠바메 2.5와 비교시 츠바메 3.0은 향상된 성능 대비 상면 면적도 상당히 줄어들었다고 덧붙였다.
2018년 선보일 예정인 AIST-AIRC(AI Research Center)의 ABCI(AI Bridging Cloud Infrastructure)는 130~200 AI-Pflops 성능을 목표로 하는, AI와 빅데이터 알고리즘 활용을 위한 인프라 구축을 목표로 하고 있다. 빅데이터와 HPC 양쪽에서 활용할 수 있도록, ‘츠바메 3.0’의 디자인에서 AI와 빅데이터 쪽으로 특화되었으며, 인프라의 구축 또한 높은 집적도와 함께 뛰어난 효율을 구현했다고 소개되었다. 그리고 일본 전체의 차원에서, AI 연구를 위한 인프라의 경우, 이런 일련의 프로젝트를 통해 3년 반 정도에 연산 성능 1000배 향상이 가능할 수 있을 것으로 소개했다.
Copyright ⓒ Acrofan All Right Reserved.


 마이크로소프트, 이그나이트 2023에서 AI 미래 여는 혁신 ..
마이크로소프트, 이그나이트 2023에서 AI 미래 여는 혁신 .. 네이버 두 번째 IDC '각 세종', "초대규모 AI , 클라우드 등..
네이버 두 번째 IDC '각 세종', "초대규모 AI , 클라우드 등..
 오토모빌리 람보르기니 최초의 플러그인 하이..
오토모빌리 람보르기니 최초의 플러그인 하이.. 로터스의 하이퍼 SUV 엘레트라, 국내 판매 가..
로터스의 하이퍼 SUV 엘레트라, 국내 판매 가..